What if your font is lying to your AI?
LegalTech's Mythos Moment
Modern legal tech stacks in 2026 are Rube Goldberg machines of open-source and proprietary products from Word to LibreOffice, to python-docx and PDFium, to tesseract, node.js and dozens of UI libraries like SuperDoc, PDF.js and Office.js. Through those pipelines are pushed artifacts of decades-old written specifications which span tens of thousands of pages.
In addition to the venerated OSS parts of these stacks exist partial, proprietary implementations of these specs. Many of these have been spun up in the last year with the assistance of coding agents.
Meanwhile even the oldest, grayest-beard OSS maintainers in the ecosystem complain of specification complexity.
What if an adversary were to try to take advantage of this complexity and the imperfections in these implementations? Could these imperfections be leveraged for a tactical legal advantage?
I reached out to my friends at the LegalQuants and recruited a team to answer this question, and you can read the analysis of the "lexploit" discussed below and about our new "Red Team" mission here: link.
Noroboto.ttf
The "noroboto.ttf" "lexploit" is straightforward: create a new malicious font definition which is embedded in a document according to the specification and lies about the Unicode representation of its glyphs.
TrueType
Among many other things, TrueType fonts like those distributed with Windows and macOS contain outlines and a cmap (or character map) which maps Unicode code points to these outlines.
The Unicode specification which is huge.
In addition to code points for scripts such as Latin and CJK, among many others, it also reserves ranges of code points for "private use".
The simplest "full obfuscation" noroboto attack works by swapping valid Unicode-encoded scripts in the subject document with Unicode code points occupying these so-called "Private Use Areas" of Unicode.
These glyphs typically render as "tofu" or some other unknown glyph in most graphical applications, or as a glyph from a fallback font definition as determined by such applications.
You can check that out here.
For "PUA" code points LibreOffice, for example, seems to fallback to Wingdings.
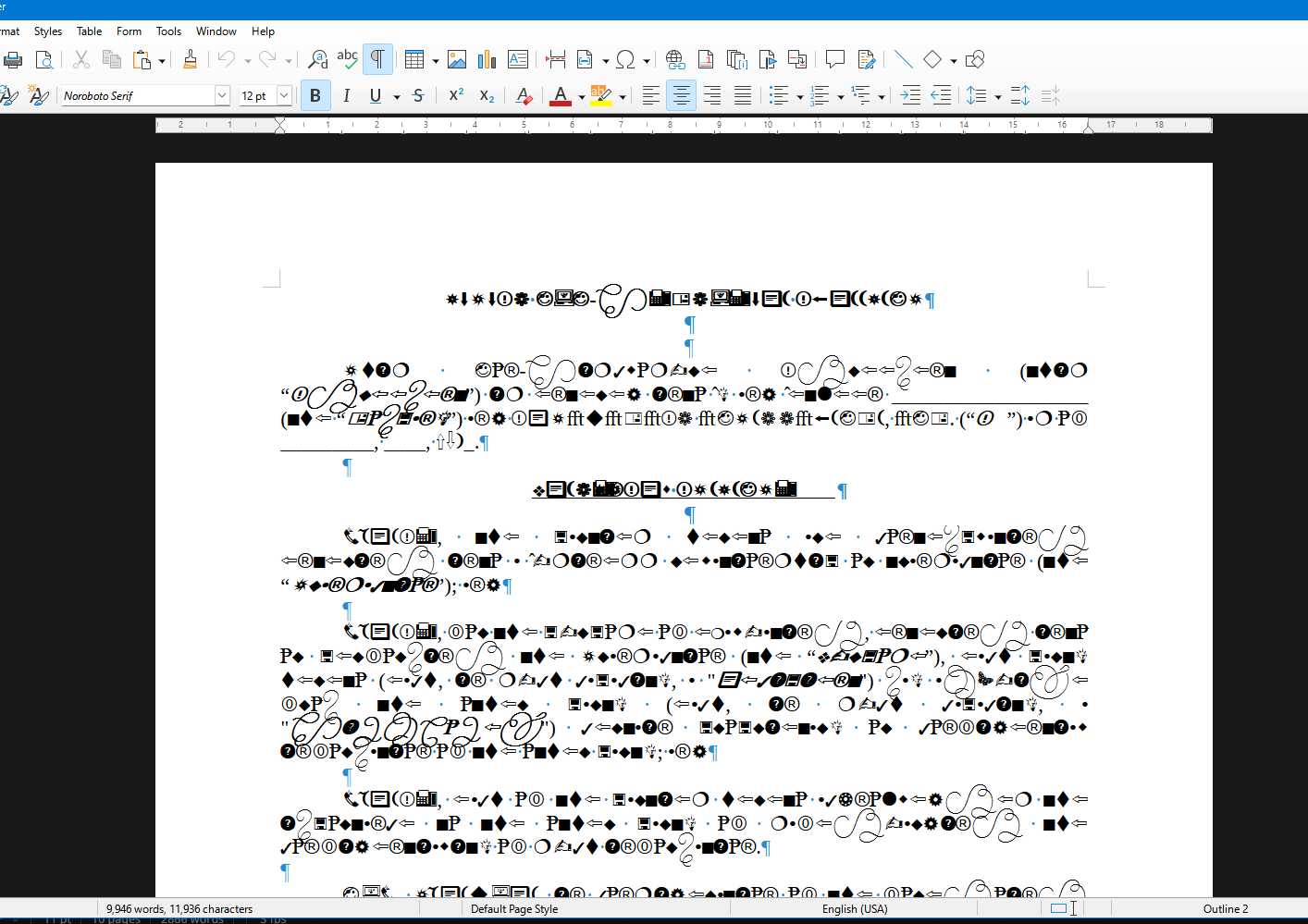
But noroboto provides a glyph for these PUA code points. And those glyphs are metric compatible with the replaced font. Their underlying Unicode mapping, however, is incomprehensible garbage.
This only works because the Word and PDF specifications allow for font definitions to be embedded in their containing documents. Embedding fonts is critical to maintain compatibility and pixel-tight rendering across platforms. And consistent rendering is especially important in legal documents where font metrics determine page layout and pagination, and page numbers can have legal meaning.
Noroboto.py
With the help of ChatGPT 5.4 we had a proof-of-concept for full obfuscation within a few hours.
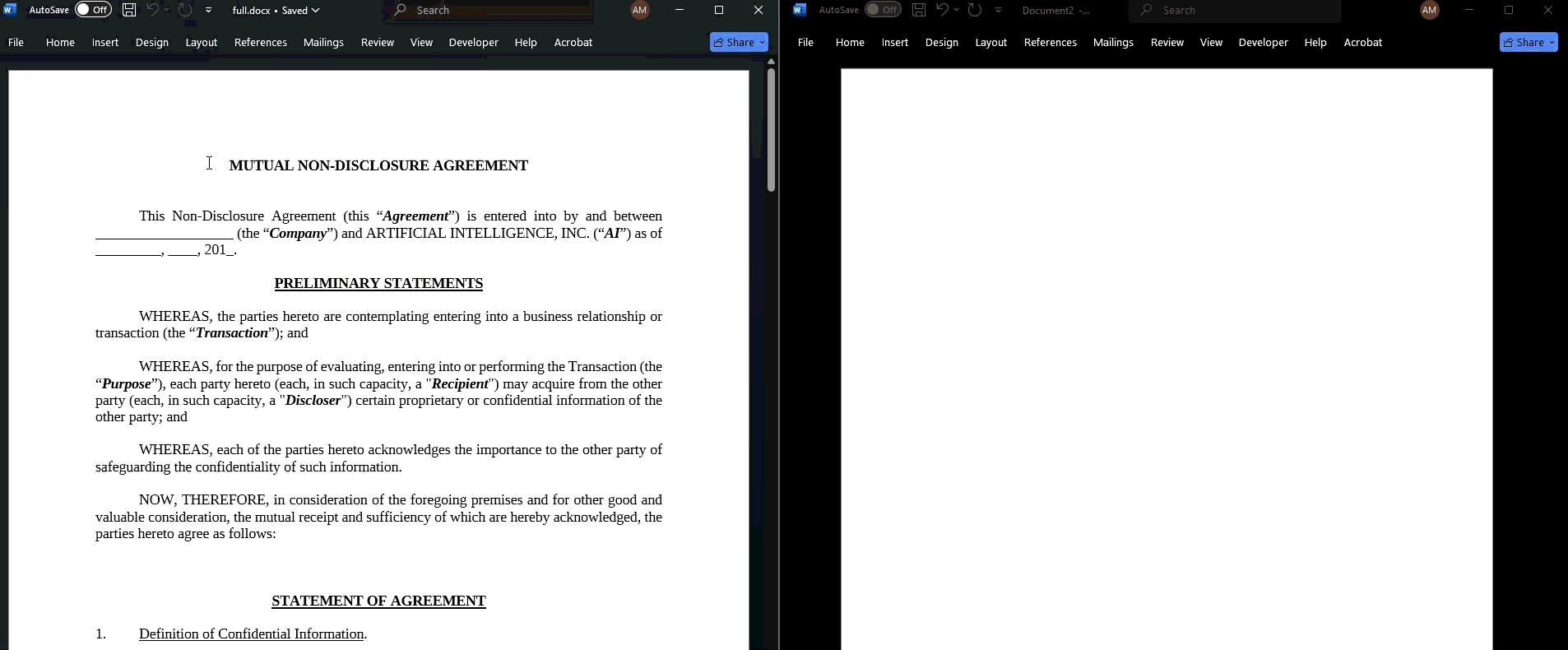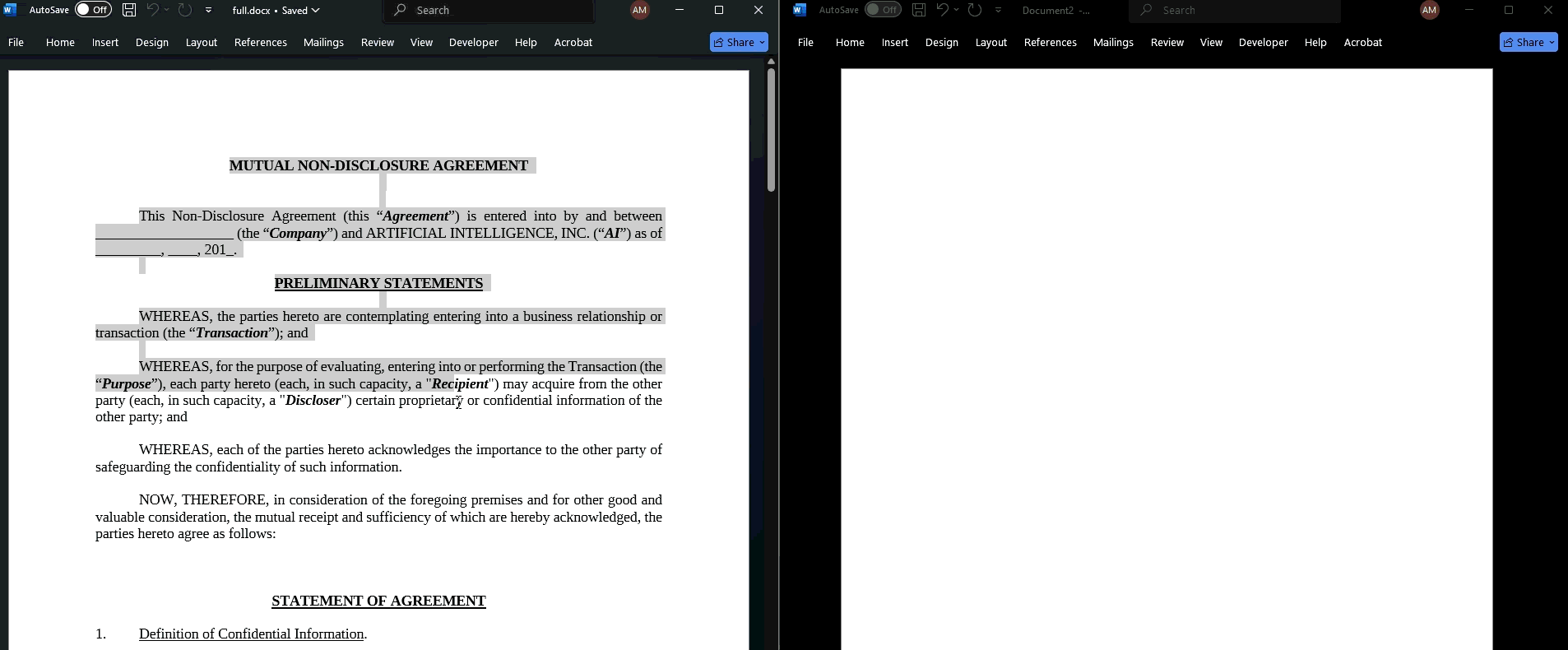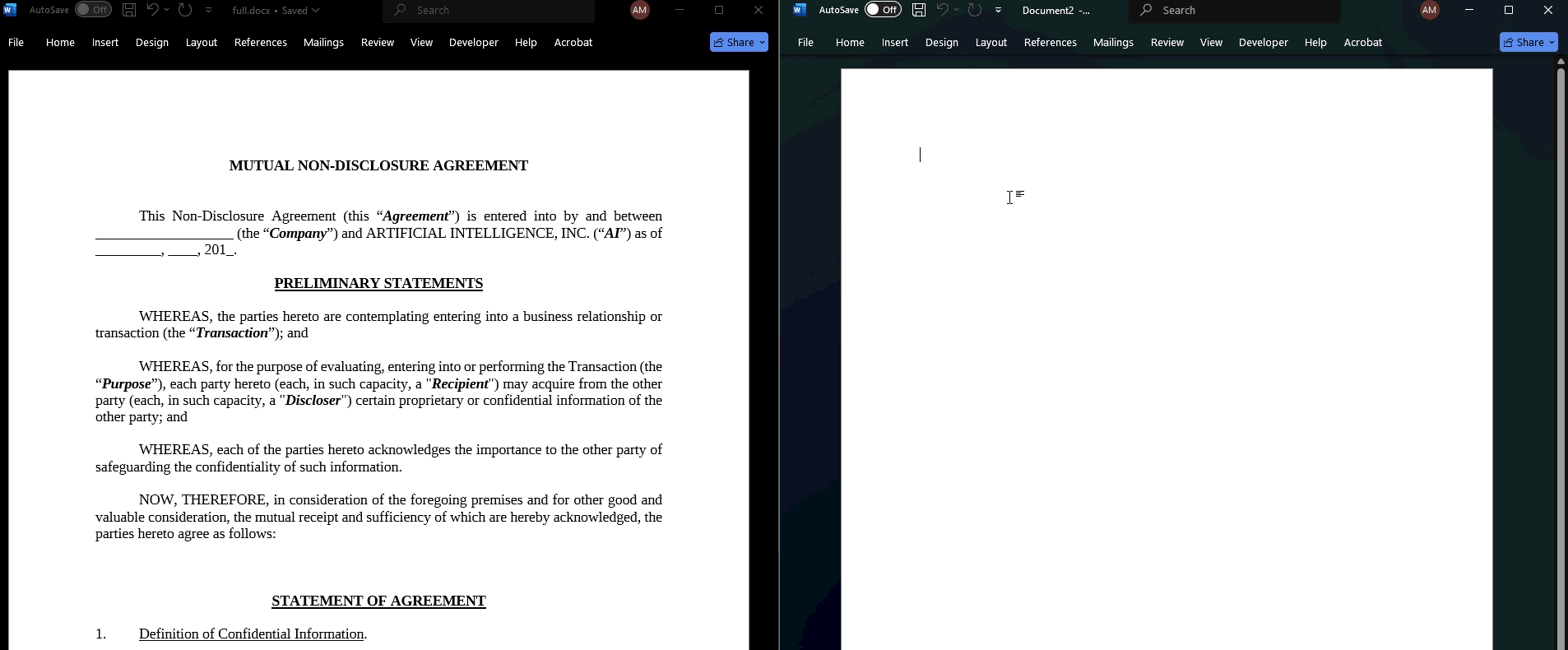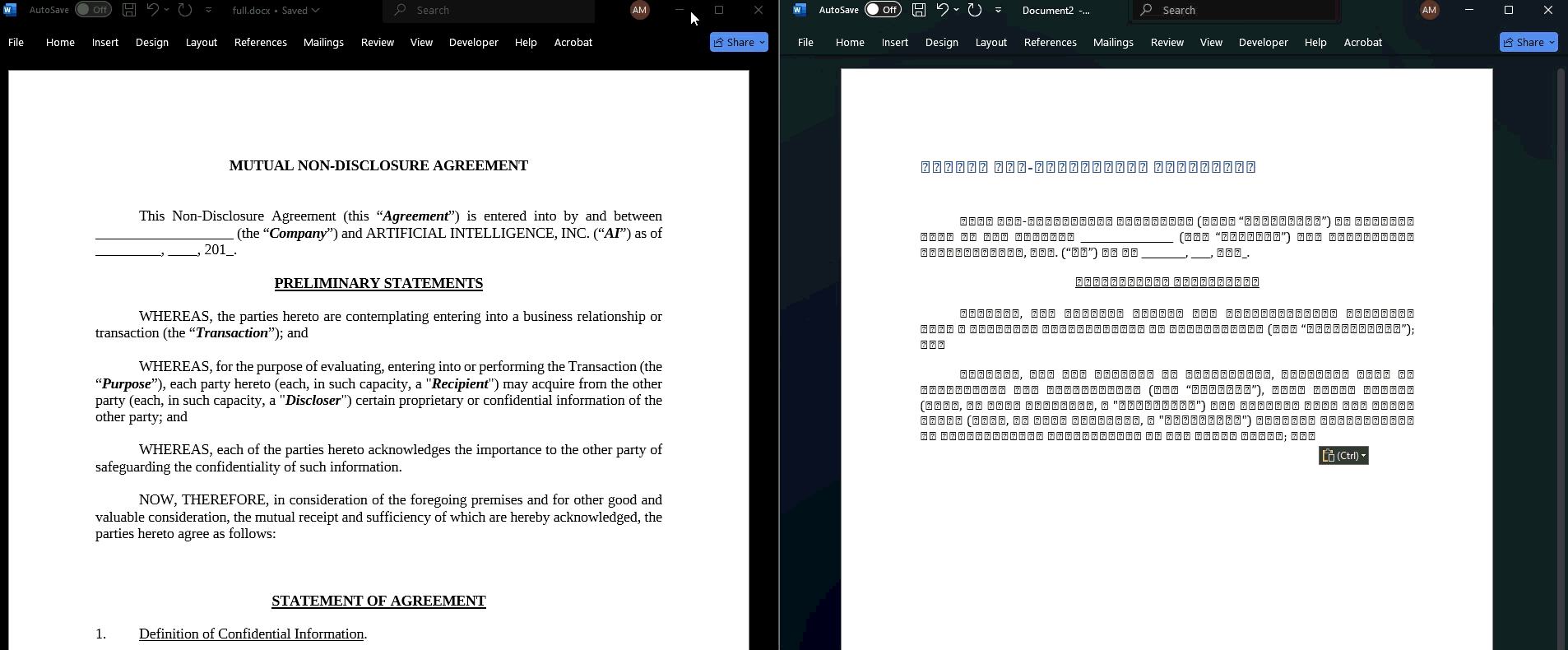
On the left of the above GIF is what the user sees. When the text is copied and pasted, however, you get the Unicode representation in an arbitrary non-Noroboto font. It's garbage. You can see a version of the code here: https://github.com/LegalQuants/noroboto.1
We opted for Python to maximize legibility, but that somewhat backfired given the "vibes heavy" implementation.2
Testing
An early testing against a version which leveraged a 1-to-1 mapping was defeated by ChatGPT 5.5 in Codex using "high effort". ChatGPT 5.5 deobfuscated in two ways.
First, given the simple PUA-to-glyph deterministic mapping, ChatGPT 5.5 treated deobfuscation as a basic cryptoanalysis exercise. It sussed out our "monoalphabetic" cipher and broke our "simple substitution cipher with side channels left intact".3 ChatGPT's second approach was to note that we had erroneously left the original "name" value in the glyph definition which could be reverted by reading the TTF.
Time to pull out the big guns: https://en.wikipedia.org/wiki/Polyalphabetic_cipher.
We updated noroboto.py in this commit to exclude that "name" field and in this commit to include a 4-to-1 mapping which is randomly applied by the text replacement algorithm.
We also perturb the font slightly across the four separate PUAs to avoid comparing the outlines and collapsing them back to a 1-to-1 mapping.
Although these changes have limitations, they seemed to supply enough stochasticity to throw off ChatGPT's simple cipher. But the frontier models in agentic harnesses with their inference-time computing modes enabled (aka "thinking") all still manage to crack the "full" obfuscation document by shelling out to something, rendering the document and OCR'ing that result.4
It turns out obfuscating the entire document is enough signal to encourage these LLMs to try different approaches.5
A live demonstration of full obfuscation is here: https://noroboto.io.
We touched on in our LegalQuants post the ethics and legality of using the Noroboto attack6, but technically the much more effective approaches are both partial obfuscation and Unicode replacement.
Extensions: Partial Obfuscation and Replacement
It turns out, agents are somewhat lazy.
Thus, if they are presented with what appears to be a document containing legible Unicode code points, they often take that apparent happy path.
Total obfuscation fails this test in the smartest models, but even the best are fooled when a document is only partially obfuscated or the text of the document is replaced.
We don't release any code on these two approaches but we present two example sets of documents in DOCX and PDF.
| Example | DOCX | |
|---|---|---|
| Full obfuscation | full.docx | full.pdf |
| Partial obfuscation | partial.docx | partial.pdf |
| Replacement | replaced.docx | replaced.pdf |
Partial Obfuscation
What's the point of partially obfuscating a legal document?
The most obvious case is to just disguise an adversarial term with a higher probability of success.
In testing our partial obfuscation example, we hid the fact that the NDA's confidentiality terms carry on to "successors and assigns".
This isn't particularly egregious but was a useful test case.
We asked the model "Does anything in this document extend my confidentiality obligations to successors or assigns?", and some, particularly inexpensive platforms, returned incorrect results for DOCX.
Now some might argue this is fraudulent if it's intended to mislead the other party, but we don't necessarily express that opinion.
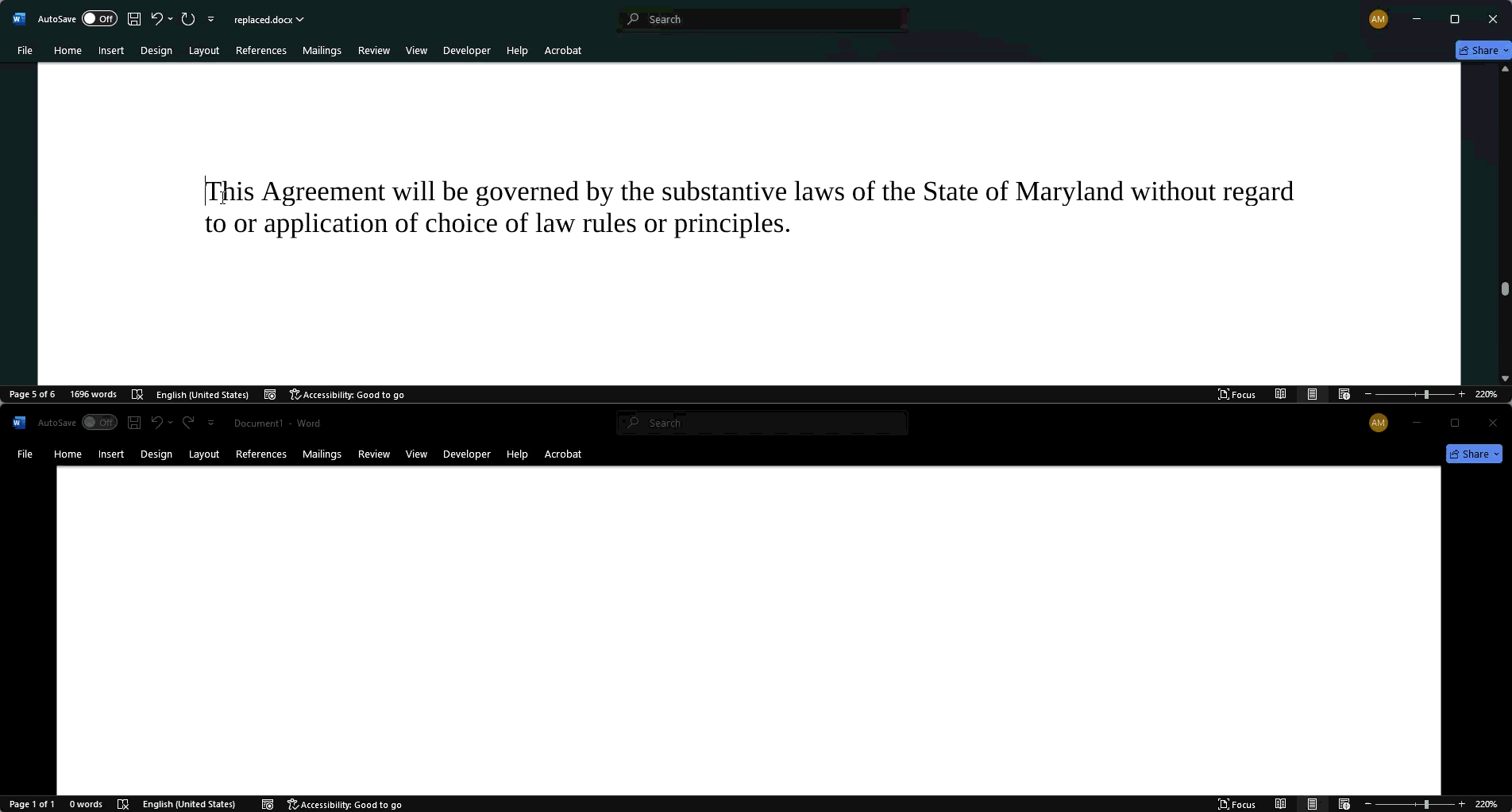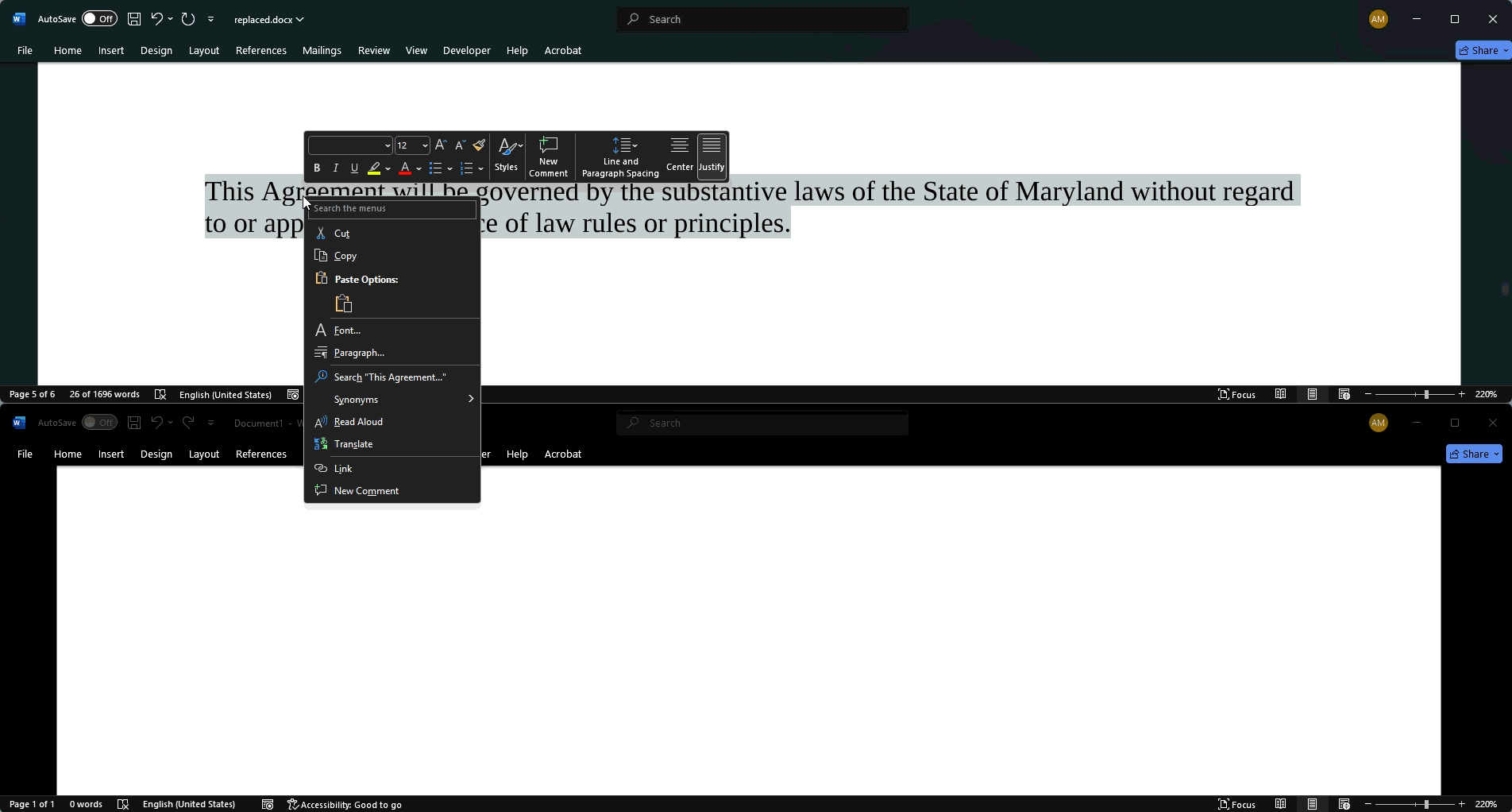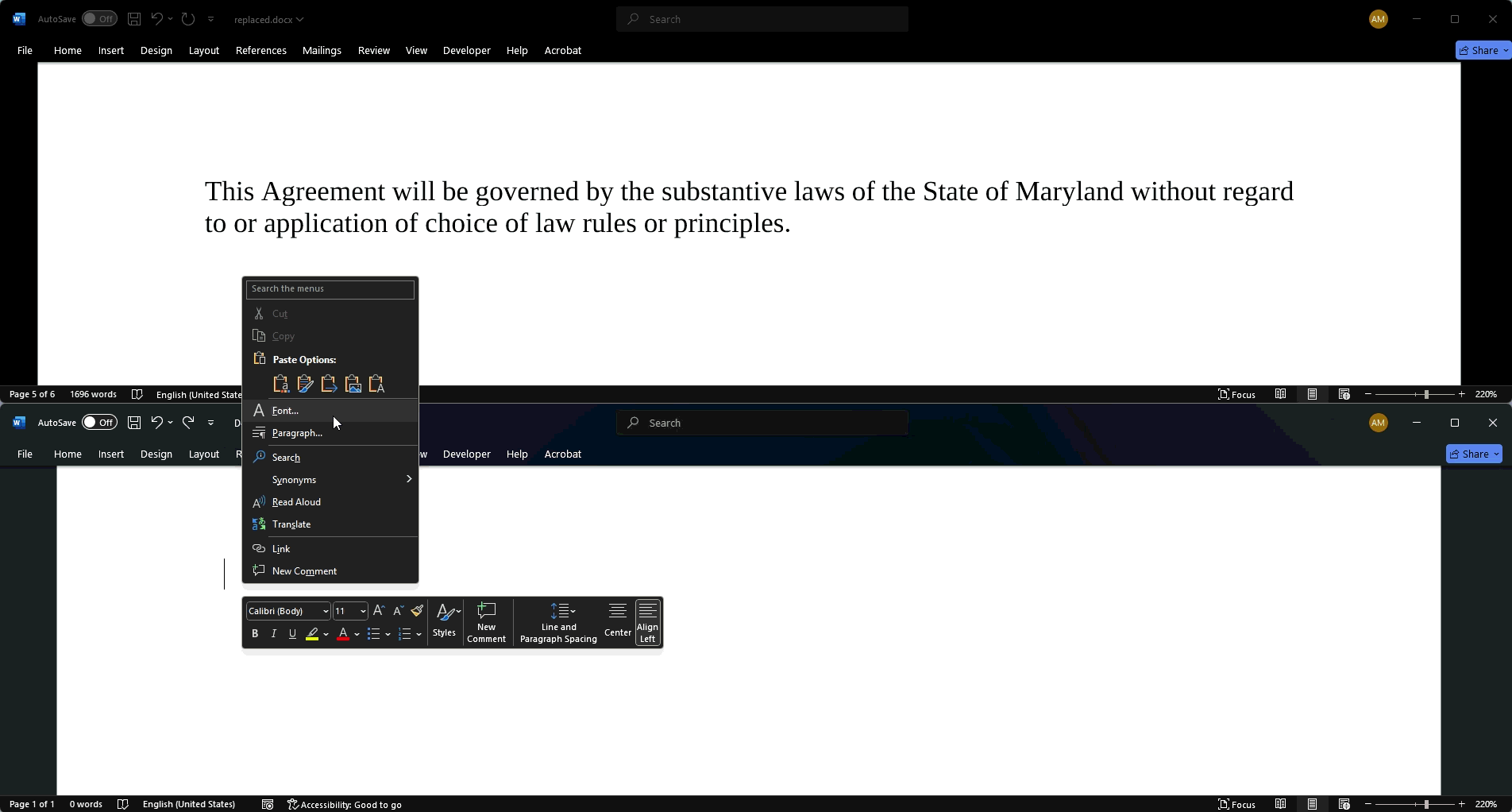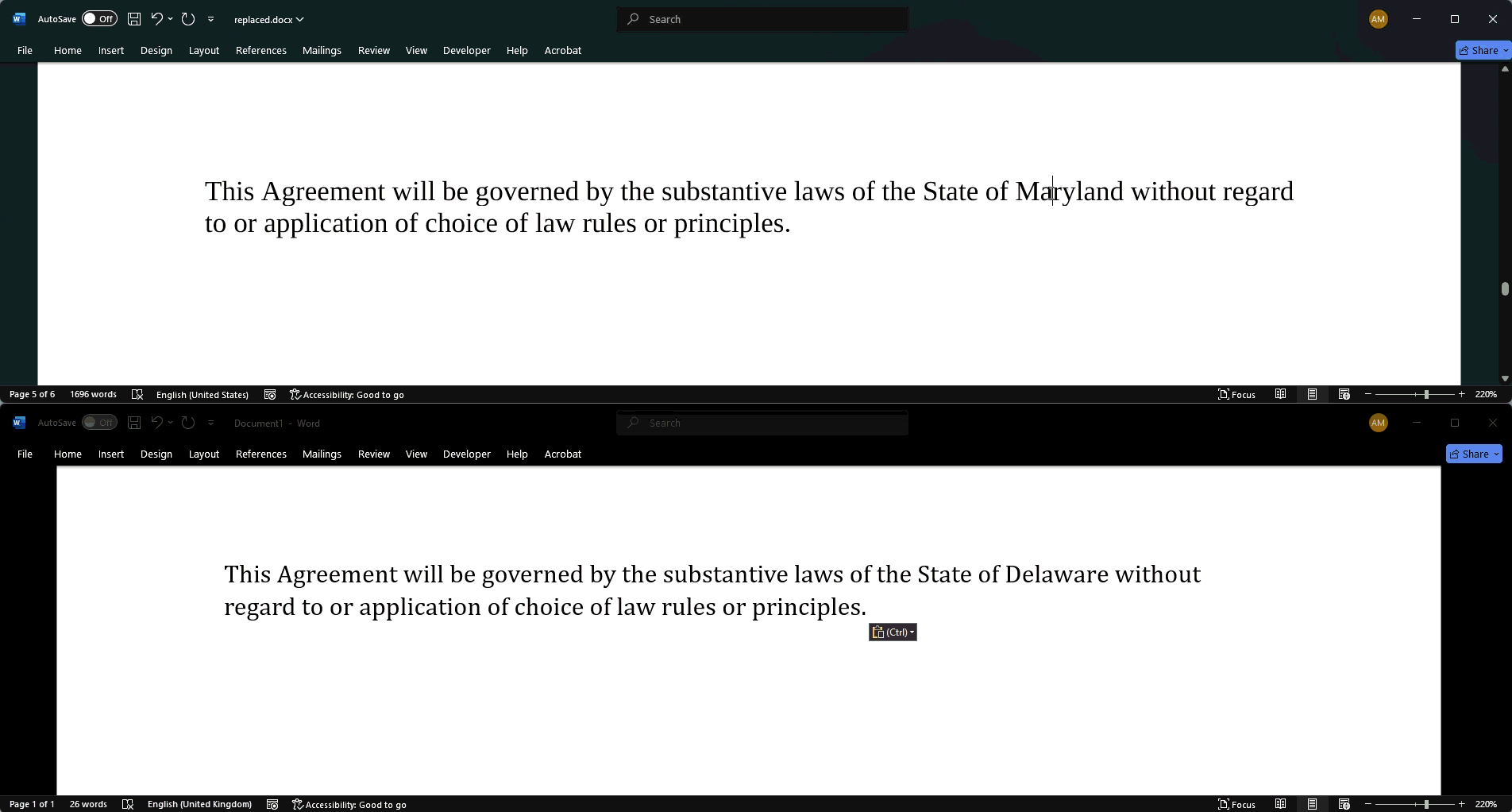
Replacement
The replacement extension of "noroboto" is the most effective.
In the replacement attack, instead of mapping the glyphs to PUA code points, we map them to Unicode values that create a different meaning.
In our example, we caused the human-visible word "Maryland" to be replaced with the Unicode representation of "Delaware".
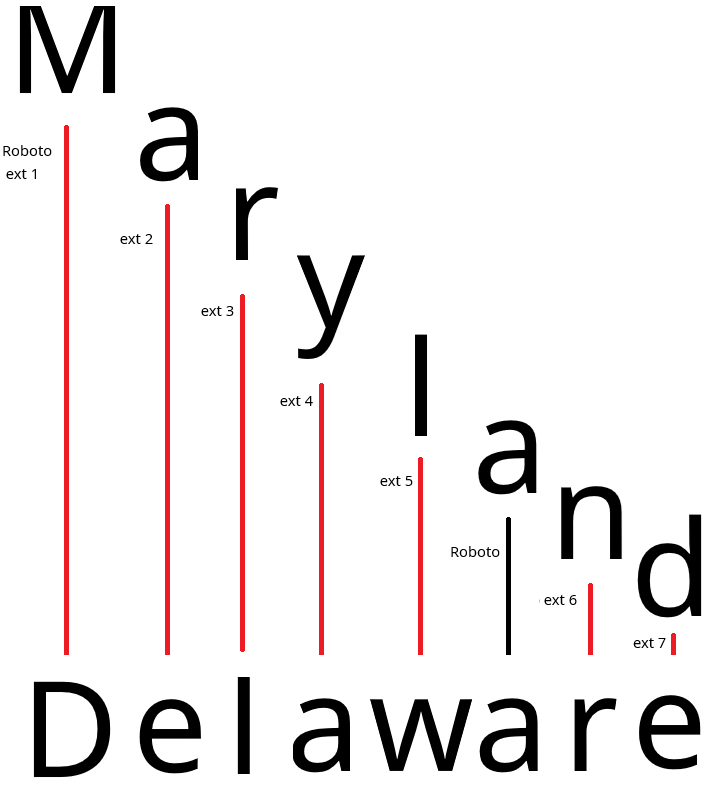
This process isn't as simple as the obfuscation attack because it requires, in the worst case, a new embedded font for each replaced glyph. In the above image, we represent each additional font as "ext [n]", but this can likely be compressed in longer replacement attacks to maximize font re-use.7
All of the platforms we tested were fooled by this approach and happily reported that the agreement provided for Delaware governing law when presented with a DOCX file.8. Most even trusted the Unicode values in PDF.
The Red Team hypothesizes that the agentic harnesses are "lazy" and prefer to rely on a facially valid Unicode string rather than undertake to render the document and run an expensive OCR computation. This laziness is likely correlated with the length of the document.
Proof of Concept Mitigation in Rust
So how might we handle this in Tritium?
Trust, but verify.
We want to retain embedded font support to ensure layout and pagination accuracy, but we first run a check against the ASCII glyphs to ensure they represent the characters they purport to represent via their Unicode cmap value.
That accuracy value is 1.0 minus the error rate, which we calculate as the Levenshtein distance between the expected ASCII string and the OCR result.
fn normalize(text: &str) -> String {
text.to_lowercase()
.split_whitespace()
.collect::<Vec<_>>()
.join(" ")
}
fn character_accuracy(expected: &str, actual: &str) -> f64 {
let expected = normalize(expected);
let actual = normalize(actual);
let distance = strsim::levenshtein(&expected, &actual);
let expected_len = expected.chars().count().max(1);
1.0_f64 - (distance as f64 / expected_len as f64)
}
With this accuracy criterion, we want to generate a font atlas which provides a pristine OCR environment such that anything other than a 1.0 accuracy score indicates a potentially deceptive font.
...
const WIDTH_PADDING: u32 = 10;
const HEIGHT_PADDING: u32 = 10;
const OCR_ASCII_VALIDATION_CHARACTERS: &str =
"thequickbrownfoxjumpsoverthelazydogTHEQUICKBROWNFOXJUMPSOVERTHELAZYDOG0123456789";
...
Here we limit our analysis to ASCII alphanumeric codes for this simple proof of concept.
We also set a padding value to ensure the glyphs in the font atlas have a sufficient buffer from the edge for OCR.
fn append_right(left: &image::DynamicImage, right: &image::DynamicImage) -> Result<image::DynamicImage> {
let left = left.to_rgba8();
let right = right.to_rgba8();
let new_w = left.width() + right.width() + WIDTH_PADDING;
let padded_right_height = right.height() + (2 * HEIGHT_PADDING);
let (new_h, left_y_offset, right_y_offset) = if left.height() > padded_right_height {
(
left.height(),
0,
left.height() - (right.height() + HEIGHT_PADDING),
)
} else {
(padded_right_height, padded_right_height - left.height(), 0)
};
let mut canvas = image::RgbaImage::from_pixel(
new_w,
new_h,
image::Rgba([0, 0, 0, 255]), // background
);
// bottom-align images
canvas.copy_from(&left, 0, left_y_offset)?;
canvas.copy_from(&right, left.width(), right_y_offset)?;
Ok(image::DynamicImage::ImageRgba8(canvas))
}
We'll now go character-by-character and render to the font atlas to keep it simple, rather than relying on a more robust shaping library like HarfBuzz to generate the image.
We provide a rather inefficient allocation algorithm to extend the font atlas for each new character.
Again, a production implementation will at a minimum pre-calculate this atlas size or use a shaping engine.
pub fn ascii_glyph_accuracy(data: &[u8]) -> Result<f64> {
let Ok(mut engine) = ocr::Engine::new() else {
bail!("Couldn't start OCR engine."); // should return an error if we don't have an OCR engine.
};
let num = ttf_parser::fonts_in_collection(data).unwrap_or(1);
let mut scale_context = swash::scale::ScaleContext::new();
for i in 0_usize..num as usize {
let Some(font_ref) = swash::FontRef::from_index(data, i) else {
continue;
};
let mut scaler = scale_context
.builder(font_ref)
.size(104.0)
.hint(true)
.build();
let charmap = font_ref.charmap();
// check ASCII codes, excluding space at 32
let mut full_image: Option<image::DynamicImage> = None;
for char in OCR_ASCII_VALIDATION_CHARACTERS.chars() {
let glyph_id = charmap.map(char);
let Some(image) = swash::scale::Render::new(&[swash::scale::Source::Outline])
.render(&mut scaler, glyph_id)
else {
bail!("Couldn't make glyph for: {char}");
};
let Some(dynamic) =
image::GrayImage::from_raw(image.placement.width, image.placement.height, image.data)
.map(image::DynamicImage::ImageLuma8)
else {
bail!("Couldn't copy swash image to image::DynamicImage.")
};
if let Some(existing) = full_image.take() {
full_image = Some(append_right(&existing, &dynamic)?);
} else {
full_image = Some(dynamic);
}
}
let Some(full_image) = full_image else {
bail!("No atlas compiled.");
};
let Ok(characters) = engine.process_impl(&full_image) else {
bail!("No characters read from atlas.");
};
let characters: String = characters.iter().map(|character| character.char).collect();
return Ok(character_accuracy(
&characters,
OCR_ASCII_VALIDATION_CHARACTERS,
));
}
bail!("Didn't find a good font.")
}
We then pass the atlas (i.e., full_image) to our platform-specific ocr::Engine implementation.
In 2026, macOS and Windows provide these facilities natively, and the Tritium implementation leverages those, while providing for a model-based approach on Linux.
In the production build, you would generally not want to re-instantiate the OCR engine for each check, but it may make sense given the infrequency with which embedded fonts are encountered in certain contexts.
Last, we run the eval.
Our simple testing harness looks like the following.
#[test]
fn noto_font_has_ascii() {
let data = include_bytes!("fonts/noto.ttf");
let accuracy = ascii_glyph_accuracy(data).expect("Glyphs should OCR.");
assert!((accuracy == 1.0));
}
#[test]
fn notoroboto_font_has_bad_ascii() {
let data = include_bytes!("fonts/noroboto.ttf");
let accuracy = ascii_glyph_accuracy(data).expect("Glyphs should OCR.");
assert!((accuracy < 1.0), "got: {accuracy}");
}
We confirm a perfect OCR for the ASCII portion of Google's Noto font, and an imperfect one for an example noroboto variant which swaps the M and D Unicode code point and glyph.
Fortunately the replacement attack requires at least a single failure in OCR although identification cannot be deterministically guaranteed.
To support others in this effort, we are working on releasing a simple open-source reference implementation which will be added as an update to this post once available.
We look forward to community feedback on this consideration and response.
-
We treat any embargo on the covered subject matter as having expired given prior art on 22 May 2025: https://arxiv.org/pdf/2505.16957 which we discovered during the course of this project. ↩
-
Some might sneer at this proof-of-concept as "AI slop", but that's somewhat the point. While a lot of commentary following Project Glasswing and Mythos announcements were focused on the strength of that model, many folks rightly pointed out that off-the-shelf frontier models were capable of the same type of bug discovery. The "Mythos moment" for legal tech may in fact be the discovery that these types of attacks are trivial to produce given those same off-the-shelf models. ↩
-
This same result is achieved by the model in Tritium which does not provide any cipher tools. ↩
-
As an aside, this is not necessarily a total loss for the attacker who has now forced the opposition out of its comfort zone. The victim's pipeline will lose a lot of layout information supplied by the DOCX specification and be required to do its own segmentation to regain structure from the boxed-characters provided by the OCR. It may foreclose automated edit suggestions via Word add-ins, for example. ↩
-
It is worth noting that free-tier models which may or may not provide "thinking" modes often not only failed to summarize the obfuscated document but also hallucinated its content. One model suggested the disclosing party was "Google, Inc." ↩
-
There are good data-protection reasons that one might legitimately obfuscate the text of its digital publications which we do not address here. ↩
-
We deliberately omit some of the technical requirements of this attack to avoid widespread replication. As noted above, even consumer-grade language models are capable of engineering these attacks with minimal guidance. ↩
-
This example has important legal consequences, but for a more lay example, imagine altering a dollar value in the same way. The human reviewer might see $2,000,000 while its LLM understood the price to be $1,000,000. ↩