One of the major benefits of Tritium as a legal drafting environment is that by default it runs on the lawyer's desktop, without any cloud services or data exportation.
This means Tritium has to be lightweight and work in diverse environments.
There were some initial reports from users that large network folders felt sluggish when opened with Tritium. Speed is Tritium's raison d'être, so that's bad.
The Single-Threaded Bottleneck
It felt slow because early versions ran the UI and document rendering on the same thread.
When an attorney opens up a folder, each document in that folder is eagerly initialized to enable realtime searching and defined term annotation. This initialization also makes the documents fast to open from the Library tree since they're already parsed and in memory.
The original process initialized only a single file each frame. That allowed some interactivity, but initialization might take a few dozen milliseconds, so the framerate dropped to single digits while a folder was being parsed. Thus, opening a folder effectively blocked the UI while each file was initialized. That looked like this:
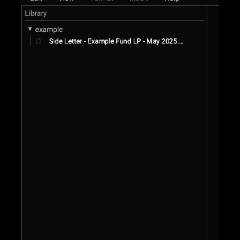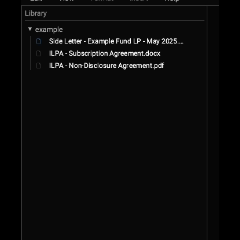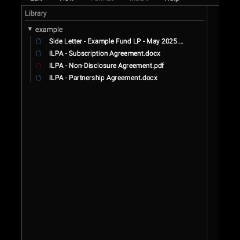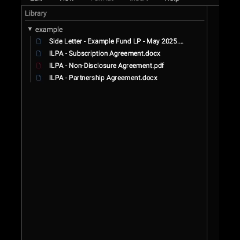
Opening files would be choppy at best and perhaps impossible while the folder loaded.[1]
The Multithreading Solution
Fixing that was straightforward.
Tritium was converted to run a client/server model with multithreading. Rust's ownership model and borrow checker makes this easier to get right. Now when the lawyer opens a folder a Watcher running on a third thread starts polling that folder. It reads the folder and updates its Observations that are a shared Arc<Mutex<std::path::PathBuf>> with the client.
Tritium renders the tree on the next frame like a normal IDE. It looks like this:
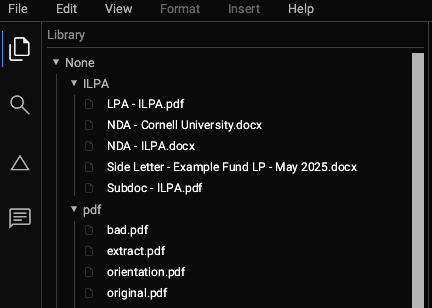
The UI thread then requests the server to initialize each of those files. It communicates with the Server thread using essentially a pair of std::sync::mpsc::channel() instances.
As they're initialized, the document icon changes to the correct color indicating that the file is in memory. That looks like this:

Working with the Library model got me thinking about what users might experience on higher-latency network drives.
Simulating Real-World Network Conditions
Time to simulate it.
Our primary commercial user base is on Windows. So we create a local network drive on a Windows box and set up clumsy to simulate a bad connection.
Clumsy is pretty cool. You can apply throttling, lag, packet dropping, etc. to your TCP streams globally.
So it turns out that throttling Tritium's bandwith works as expected. We apply a 100kb limit, and, sure enough, Tritium subtly indicates that the files are being parsed slower as their icons slowly turn from dark gray to red or blue.
Since we prioritize clicked documents for rendering, this bandwidth throttling doesn't have much apparent effect to the end-user. At 1 megabit/s things are perfectly usable. Rates below that are not our issue, or ones we can much solve anyway.
Adding a lag of only 50ms inbound and outbound, however, paints a surprisingly different story. The application crawls to a halt.
When Latency Becomes the Enemy
Fifty milliseconds of latency seems like a reasonable model of a wide area network connection. This is concerning.
Since the read() calls just slurp the file one-way, this performance degredation may have something to do with our Watcher's loop. A bit of investigation rules that out, however. It's not the polling.[2]
Diving Into the Read Implementation
This is roughly our code to read in each file:
pub(crate) fn slurp_path(path: &std::path::PathBuf) -> Result<..> {
let Ok(mut file) = std::fs::File::open(path) else {
return Err(..);
};
let mut bytes = Vec::new();
if file.read_to_end(&mut bytes).is_err() {
return Err(..);
}
Ok(bytes)
}
The read_to_end() implementation on my machine gives a good summary of one potential issue for Windows:
// Here we must serve many masters with conflicting goals:
//
// - avoid allocating unless necessary
// - avoid overallocating if we know the exact size (#89165)
// - avoid passing large buffers to readers that always initialize the free capacity if they perform short reads (#23815, #23820)
// - pass large buffers to readers that do not initialize the spare capacity. this can amortize per-call overheads
// - and finally pass not-too-small and not-too-large buffers to Windows read APIs because they manage to suffer from both problems
// at the same time, i.e. small reads suffer from syscall overhead, all reads incur costs proportional to buffer size (#110650)
//
In other words, the implementers are making trade-offs on chunk size based on expected use cases. Without diving too deep into the implementation, the issue might be that read_to_end() is chunking the read into a number of serial requests that are each hit by the 100ms lag.
ChatGPT recommends something like the following:
use std::{fs::File, io::{Read, BufReader}};
let f = File::open(r"Z:\path\file")?;
let mut r = BufReader::with_capacity(1<<20, f); // 1 MiB
let mut buf = vec![0u8; 1<<20];
while r.read(&mut buf)? != 0 { /* process */ }
The idea is to use a buffered reader with a large capacity to encourage the OS to read larger chunks.
But that actually doesn't do the trick because the implementation of r.read() still leverages the File implementation of read_to_end.
More importantly, file size doesn't even seem to have much to do with it.
We set clumsy to 50ms lag on inbound and outbound localhost ipv4 traffic and isolate the read code on an empty file just to establish a baseline:
The Shocking Discovery: Empty Files Take Forever
#[test] fn test_slurp_path_over_network() -> Result {
let path = std::path::PathBuf::from("Z:\\empty.txt");
let start = std::time::Instant::now();
let _ = slurp_path(&path);
println!("slurp took: { OK }ms", start.elapsed().as_millis());
}
// slurp took: 1781ms
Wait.
Reading an empty file took 1781ms from a network drive with 100ms round-trip latency!?
Shouldn't that be more like... say... 400ms assuming a three-way handshake, then a roughly zero byte payload?
Benchmarking some simple implementations of open and slurp_path(), we can see that over half the time is spent just opening the file.
pub(crate) fn open(path: &std::path::PathBuf) -> Result<std::fs::File, ()> {
let now = std::time::Instant::now();
let Ok(file) = std::fs::File::open(path) else {
return Err(());
};
println!("open took: {}ms", now.elapsed().as_millis());
Ok(file)
}
pub(crate) fn slurp_path(path: &std::path::PathBuf) -> Result<Vec<u8>, ()> {
let mut file = crate::fs::open(path)?;
let mut bytes = Vec::with_capacity(1024 * 1024);
if file.read_to_end(&mut bytes).is_err() {
return Err(());
}
Ok(bytes)
}
// open took: 963ms
// slurp took: 1772ms
Turning clumsy off and re-running that little test script yields a slurp time of 0ms. There initially seems some promise in configuring various Windows-specific std::fs::OpenOptions options, but these actually don't move the needle.
The SMB Protocol Limitation
It seems like the speed of light[3] here is limited by the Sever Message Block protocol that underlies standard Windows network drives.
Since Tritium only cares about reading at this point, there's not much benefit in caching or trying to re-use these file handles to amortize the open cost.
But for now we'll still be limited by the chatty protocol in a high latency environment.
Bummer.
The Path Forward
The answer is to parallelize the directory reads in the future to improve performance. tokio here we come!
[1] In fact, the Web Preview doesn't yet use multithreading and suffers from this performance issue.
[2] The Watcher polls every 2 seconds. Adjusting that to 30 seconds has no effect. The Library tree shows up in a reasonable (but slow) timeframe, and the file loading is still slow.
We can speed the Library tree up significantly by not requesting entry.metadata() for each result from std::fs::read_dir() since that metadata() call requires a round-trip to the network drive. read_dir() entries include a file_type() option which can confirm if it's a directory or not.
That's good.
But something is up with our Server's read() call.
[3] One interesting point made by John Carmack in his interview with Lex Fridman is to focus on the speed-of-light performance metric. That's the theoretical maximum speed your operation can be performed.